The short version.
- Gorgias caps the API at 40 requests every 20 seconds on an API key, 80 on OAuth2, per account (Enterprise gets a tighter 10-second window).
- Hit the cap and you get a 429. Two headers tell you what to do: X-Gorgias-Account-Api-Call-Limit (your live usage) and Retry-After (how long to wait).
- Written for Founders, COOs, and Heads of CX at $10M-$100M Shopify brands running Gorgias with an in-house dev who keeps hitting the limit.
Your Gorgias integration works fine in testing. Then you run the nightly export, or the migration, or the analytics sync against a full account, and it starts throwing 429s halfway through. The job dies. The data never lands.
There's a quieter version of the same problem that costs more. A customer is on the phone, your integration tries to pull their order from Gorgias, and the request gets throttled because a background job is draining the same budget. The agent says "let me check and call you back." That missed call doesn't come back.
We run AI phone support in front of Gorgias for 50+ Shopify brands, which means we hit this API in production, live, while customers are on the line. So this is the rate-limit guide from the seat of someone who has to keep it working under real load, not just read the docs. If you want the full picture of the API itself, our Gorgias API overview covers auth, objects, and build-vs-buy. This page stays on one thing: the limit, and how to stop it from breaking you.
If your Gorgias data is arriving late and the phone is the channel paying for it, book a 30-min call and we'll show you where the leak actually is.
The actual Gorgias API rate limits
Here are the numbers straight from the Gorgias developer docs. The limit depends on how you authenticate.
| Authentication | Limit | Window | Rough steady rate |
|---|---|---|---|
| API key (Basic auth) | 40 requests | per 20 seconds | ~2 requests/second |
| OAuth2 app | 80 requests | per 20 seconds | ~4 requests/second |
| Enterprise account | same per-request count | tighter 10-second window | bursts reset faster |
The single most important thing to know: the limit is per account, not per key. Your migration tool, your reporting sync, and your phone or chat integration all draw from the same 40 or 80 requests. If three systems hit the account at once, they fight over one budget, and the one that loses gets the 429. This matters most for brands running a busy Shopify helpdesk with several tools wired into the same account.
If you're polling Gorgias on a tight schedule, build OAuth2 instead of an API key. Doubling from 40 to 80 per window is the difference between a sync that finishes and one that stalls at scale. The per-second framing you'll see in some guides (around 2 per second on lower plans, more on higher ones) is just the 20-second window divided out, so treat the official per-window numbers as the source of truth.
How the leaky bucket actually works
Gorgias uses a leaky bucket algorithm, and the name describes it well. Picture a bucket with a small hole in the bottom. Every request you make pours a little water in. The hole drains at a steady rate the whole time.
As long as you pour slower than it drains, the bucket never fills and every request goes through. Send a burst and the water rises. Fill it to the top and the next request overflows, which is your 429. Then you have to wait for the bucket to drain back down before requests succeed again.
This is why your sync passes every small test and then dies on the real account. Twenty requests in a tight loop fit under the cap. Two thousand records in the same loop overflow the bucket within seconds. The fix is never "send less data." It's "send it at a pace the bucket can drain."
The two headers Gorgias gives you (read them)
Every response from the Gorgias API carries headers that tell you exactly where you stand. Two of them matter, and most teams ignore both until something breaks.
- X-Gorgias-Account-Api-Call-Limit shows your current usage as used/limit, for example 10/80. This is your fuel gauge. You can read it on every response and slow down before you ever see a 429, instead of crashing into the wall and recovering after.
- Retry-After appears when you've been throttled. It's the number of seconds to wait before trying again. Respect it literally. Retrying sooner just earns another 429 and resets the clock.
You may also see standard X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset headers depending on your client, but the Gorgias-specific account-call-limit header is the one to watch because it's scoped to the budget you actually share across integrations.
If you read one header, read X-Gorgias-Account-Api-Call-Limit on every response and throttle yourself at around 80% of the cap. Self-pacing beats reacting to 429s every time.
How to handle a 429 (with a real retry function)
When you hit the limit, Gorgias returns HTTP 429 Too Many Requests and drops the request. It does not queue it for you. Retrying is on you, and how you retry decides whether you recover cleanly or make it worse.
The proven pattern is capped exponential backoff with jitter, and it has three rules. Respect Retry-After when it's present. Back off exponentially when it isn't. Add a random jitter so that if several workers hit the limit at once, they don't all retry on the same tick and create a retry storm.
Here's a real version you can adapt:
async function gorgiasRequest(call, attempt = 0) {
const res = await call();
if (res.status !== 429) return res;
const maxAttempts = 6;
if (attempt >= maxAttempts) throw new Error("Gorgias rate limit: gave up");
// Respect Retry-After if present, else exponential backoff with full jitter
const retryAfter = Number(res.headers.get("retry-after"));
const base = 1000; // 1 second
const backoff = Math.min(60000, base * 2 ** attempt);
const waitMs = retryAfter ? retryAfter * 1000 : Math.random() * backoff;
await new Promise(r => setTimeout(r, waitMs));
return gorgiasRequest(call, attempt + 1);
}
Cap the attempts so a failing job can't loop forever. For background jobs, 5 to 7 attempts with a max backoff around 60 seconds is sensible. For anything a customer is waiting on, keep it to about 3 attempts and a short total timeout, because nobody on hold wants to wait through a 30-second backoff chain.
Which Gorgias endpoints burn your budget fastest
Not all calls cost the same in practice. Some operations turn one logical task into dozens of requests, and those are the ones that overflow the bucket. Ranked by how fast they drain your budget:
- List endpoints with hydration. "Pull every open ticket with its messages and customer" sounds like one job. It's a list call plus a follow-up call per ticket, so 100 tickets can become 200-plus requests in a few seconds.
- Per-record enrichment loops. For each ticket, fetch the customer, then fetch their order. The multiplication is what kills you, not any single call.
- Bulk imports, exports, and migrations. The classic "works in dev, dies at scale" case. Gorgias has even shipped infrastructure improvements aimed at these workloads, which tells you how common the failure is.
- Live lookups that collide with a batch job. A single order lookup is cheap. But run it while a migration is draining the shared account budget and it 429s at the exact wrong moment, which for a phone brand is mid-call.
The pattern across all four: the danger isn't a heavy endpoint, it's many light calls fired faster than the window allows. Find your loops first. Most of those loops exist to keep WISMO automation fed, so that's usually where the budget goes.
How to stay under the limit
Once you know the bucket drains at a fixed rate, staying under it is mostly about making fewer, smarter calls. Four levers, cheapest first.
- Set limit=100 on every list call. Gorgias moved to cursor-based pagination, and the limit parameter defaults to just 30 with a max of 100. Bumping it to 100 cuts your request count for the same data by more than three times. Then follow next_cursor until it returns null. This is the single biggest, cheapest fix.
- Use webhooks instead of polling. Polling every minute for new tickets spends requests even when nothing changed. A ticket-created or ticket-updated webhook pushes the event to you and costs zero of your request budget. If you're syncing order data for order-status answers, webhooks keep that data fresh without burning the window.
- Queue and spread your requests. Instead of firing a loop as fast as the code runs, push calls through a queue that releases them at a steady pace under the window cap. The job takes a little longer and actually finishes.
- Schedule heavy jobs off-peak. Run migrations and full exports when your live, customer-facing lookups aren't competing for the same account budget. Don't let a nightly export and a daytime phone lookup share a window.
Do these four and most "random" 429s disappear, because they were never random. They were a loop, a default page size, or two jobs sharing one budget.
What a throttled sync actually costs you
A 429 looks like a developer problem. It isn't. When Gorgias data arrives late, the order context and ticket history aren't in the helpdesk when your team or your phone agent needs them. The customer asks "where's my order," and the answer becomes "let me check and call you back."
That's expensive for a $10M-$100M brand. WISMO is 30-40% of tickets and over 50% at peak, so the exact moment your sync chokes is the moment most of your contacts need an answer. And callers don't wait. 85% of people who can't reach a person never call back, and 62% switch to a competitor. This is the same leak that makes after-hours phone coverage so valuable, and it's worth fixing inside your broader ecommerce customer service plan, not treating it as a one-off bug.
Run the math on even one rep's worth of repeatable order-status calls. A 6-rep CS team at roughly $4,000 loaded per rep is $24,000 a month, and 70% of those calls are the same questions over and over. A throttled integration doesn't just annoy your dev. It pushes that repeatable volume back onto humans and onto voicemail. WashCo, a Shopify brand we launched, recovered $22,664 in its first 7 days on the phone once those calls actually got answered.
If your Gorgias sync is dropping data and your phone is where it shows up, book a 30-min call and we'll do the math on your actual call volume.
Where Ringly fits (the live-call lookup problem)
Ringly.io is AI phone support for Shopify brands. The AI answers inbound calls 24/7, finds orders in your store, handles returns and product questions, and escalates the calls that need a human cleanly to Gorgias or whatever helpdesk you already run. You keep your current number, your current stack, and your workflows.
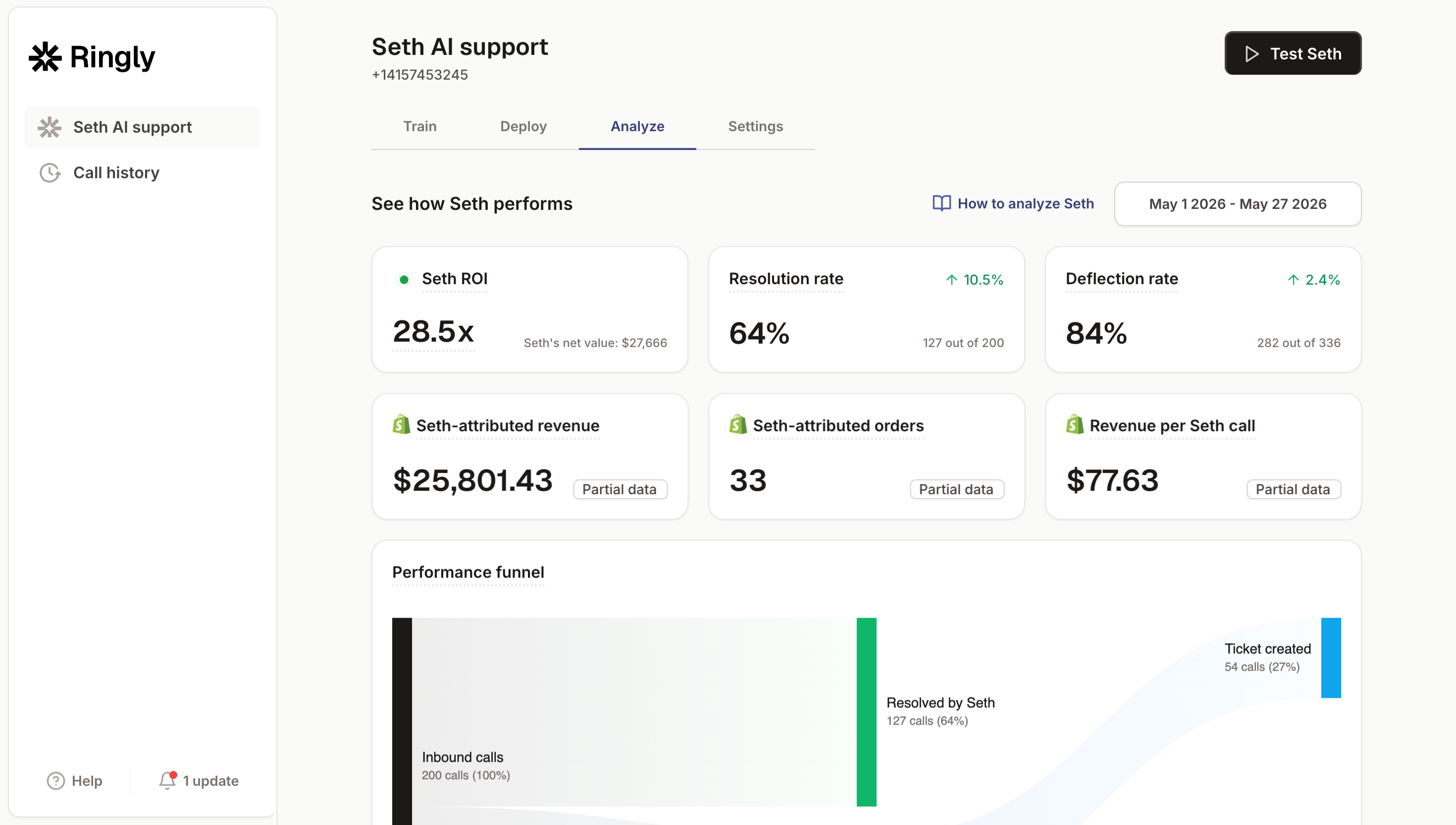
The rate-limit reason it matters here: the worst place to catch a 429 is a customer or order lookup during a live call. That single lookup is cheap, but it shares your account budget with every batch job, and when it loses, the customer hears a stall. Across 50+ brands, the AI resolves 73% of inbound calls autonomously at roughly $0.42 per resolved call, which means far fewer of those fragile, time-sensitive lookups land on a stressed human at the worst moment. For higher-volume stores, that's the difference between a Shopify Plus support operation that scales and one that staffs up every peak. If you ever do outgrow the platform, our Gorgias alternatives breakdown covers the helpdesk side too.
Plans run Grow at $349/mo, Pro at $799/mo, and Enterprise custom, all backed by a 65% resolution guarantee or we refund the last 3 months. You can be live in under an hour. It won't fix your migration script, but it does take the most fragile, repeatable phone calls off the table so a throttled sync isn't also a lost-sale problem.
Frequently asked questions
What is the Gorgias API rate limit? Gorgias allows 40 requests per 20-second window on an API key and 80 per 20-second window on an OAuth2 app, enforced per account using a leaky bucket. Enterprise accounts get the same request counts on a tighter 10-second window.
What happens when you hit the Gorgias rate limit? The API returns a 429 Too Many Requests and drops the request. It includes a Retry-After header telling you how many seconds to wait, and you have to retry the call yourself, ideally with exponential backoff.
Does the Gorgias rate limit differ by plan? The per-request counts are the same, but Enterprise accounts use a tighter 10-second window so the budget resets faster. More importantly, the limit is per account, so every integration on that account shares the same 40 or 80 requests.
How do I avoid Gorgias 429 errors? Set limit=100 on list calls to make far fewer requests, use webhooks instead of polling, queue requests so they release at a steady pace, and watch the X-Gorgias-Account-Api-Call-Limit header so you throttle yourself before hitting the cap.
Is the Gorgias limit per API key or per account? Per account. If your migration tool, analytics sync, and phone integration all run at once, they share one budget, which is why one of them randomly starts throwing 429s.
Which headers does Gorgias send for rate limiting? The two that matter are X-Gorgias-Account-Api-Call-Limit, which shows your usage as used/limit like 10/80, and Retry-After, which tells you how long to wait after a 429.
Talk to us

If your Gorgias data is arriving late and the phone is the channel paying for it, a 30-min call is the fastest way to see what's leaking and what it's costing. We'll look at your real call volume and map what the AI can take off your team.
The 3-layer guarantee.
- Live in 14 days or it's free until launched.
- 65% resolution in 90 days or we refund the last 3 months of subscription fees.
- We keep working free until we hit it.
Ruben (Ringly co-founder) takes these calls personally.